Building a Python Job Processor in Golang
For those of you who know Python and also dabble with machine learning and artificial intelligence, you know that some of the Python libraries like scikit-learn and NumPy are incredibly useful and take care of some heavy-lifting. As a small team at Amper, we make heavy use of these packages for signal classification and identification as it saves us time and effort in the early stages. Our product requires for us to run multiple classification tasks across different machines at any given time. I’ve worked with the multiprocessing portion of Python previously, but building simple concurrent programs always was a challenge.
On the other hand, I’ve had some experience writing simple task processors with golang that allow for job pools and simple concurrency. Rob Pike’s talk on concurrency patterns in Go was especially helpful if you’re curious. Having used Go for similar tasks before, we decided to use it as a job delegation ‘wrapper’ for the individual classification tasks in Python. By carefully designing the interface in-between the two, we were able to build a simple job processor that allowed for us to quickly get up and running.
Below is a small diagram of how our service works at a high level. As you can see, the python scripts are completely stateles. They load their model parameters from a pickled file on the server, and the data to analyze is passed over from the go job processor using temporary files as we will see.
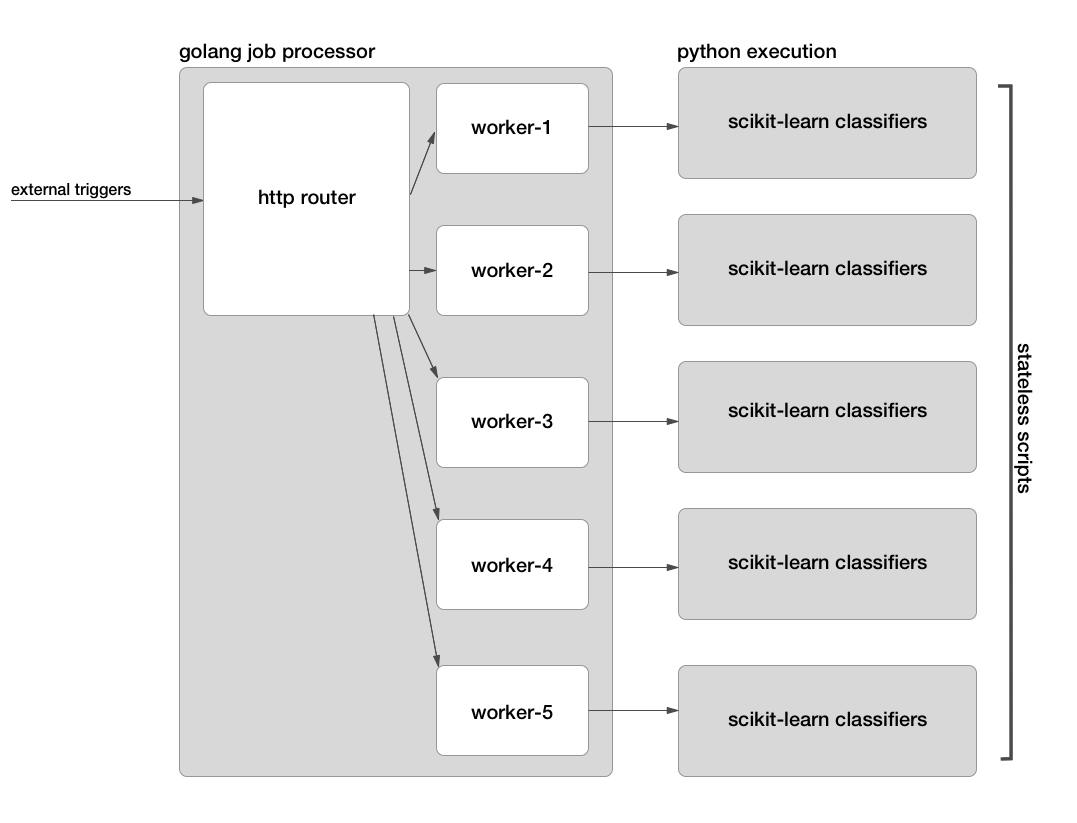
Golang-Python Interface
As you can imagine, one of the trickiest components to this system is to ensure reliability and safety across this language boundary. Things like error handling, logging, and monitoring become more complicated and take a little more thought than normal. Before I go further, here’s a shout-out to an excellent blog post that gave me inspiration on how to approach this.
Passing Data
One of the key components to keeping the Python code stateless is to hand all the inputs that the script requires on-call. Our Python code has no knowledge of databases, other services or complicated configuration. One of the most important pieces it needs is the actual signal that we want to classify. In our use case, the signal is a few hundred datapoints long, too much to pass as a command line argument.
We set up our job processor to produce a temporary JSON file in our /tmp/
directory. The full path of that temporary file is then used as an argument to
the Python script where the data is loaded before getting cleaned up by the job
processor at the end. The nice thing here is that any other configuration
variables or attributes can get passed via this same route, especially
complicated ones.
Error Handling and Logging
Now that we can’t catch exceptions normally, we had to come up with a simple protocol so that our Python code could communicate to the job worker that there was an error. We ended up coming with utility functions similar to the one below. It’s very simple code, but it prefixes any message with a constant. We also use the same concept for sending debug logs to golang.
def error(message):
"""
custom error handling so that the go worker can process it correctly
"""
print("ERROR: %s" % message)
Our go worker reads in the output using bufio.NewScanner and its Scan()
method. Here’s some simple code below:
for scanner.Scan() {
output := scanner.Text()
switch {
case strings.Contains(output, "ERROR:"):
processingError = errors.New(fmt.Sprintf("Error while running script: %s", output))
return
case strings.Contains(output, "LOG:"):
log.Printf("Logging output of script: %s", output)
case strings.Contains(output, "OUTPUT:"):
log.Printf("Received final output: %s", output)
// handle output
return
}
}
As you can tell, our worker handles three output cases, errors, logs, and the final output. In the cases of errors and output, we finish scanning and end this portion of the job before moving on. Or you can simply log what you get and move on. As a note, it’s a good idea to have a safe default just in case your Python script has some unforeseen logging output you don’t control.
Another note is that the error handling on the Go worker must correctly log and
handle these errors. All of my Worker interfaces have a Cleanup() method
that handles any leftovers after spawning this Python job. Any leftover files,
open connections, etc. must be cleaned up regardless of success or failure.
Additionally the worker must then be returned back to the pool for future
processing.
Golang Job Processor
Next, let’s look at how our Go service delegates its workers to run multiple jobs at once. A naive approach might be to use a goroutine and spawn a new goroutine for each incoming request. The problem with that approach is that some of the Python computing tasks are pretty CPU intensive, and spawning an unbounded number of these will bring our server grinding to a halt pretty fast. We went with a fixed size worker pool that makes heavy use of Go channels.
As tasks come in via HTTP requests, they get put on the job queue where they get processed as workers become available. At the implementation level, this queue is also a channel that our http handlers place incoming tasks in. Another go routine that spawns at startup uses a switch statement to receive jobs and pass them to the workers. Let’s look at some skeleton code below:
const (
POOL_SIZE = 10
)
var workerPool chan Worker
var pendingJobs chan Job
func init() {
log.Printf("initializing server")
workerPool = make(chan Worker, POOL_SIZE)
pendingJobs = make(chan Job, 100)
jobOutput = make(chan int, 100)
for i := 0; i < POOL_SIZE; i++ {
worker := Worker{id: fmt.Sprintf("worker-id-%d", i+1)}
workerPool <- &worker
}
}
func monitor() {
for {
select {
case s := <-pendingJobs:
log.Printf("processing job with ds: %d", s.GetDatasource())
go getWorker().Process(s)
}
}
}
func getWorker() Worker {
select {
case worker := <-workerPool:
return worker
}
}
func main() {
go monitor()
http.HandleFunc("/", handler)
http.ListenAndServe(":8084", nil)
}
func handler(w http.ResponseWriter, r *http.Request) {
log.Println("Received request: ", r.URL.Path[1:])
pendingJobs <- &newJob
}
monitor is the method mentioned earlier that simply listens to the
pendingJobs chan for incoming messages. It chains getWorker() and
Process() together to 1) wait until a worker is available, and then 2)
actually process the given job. You’ll notice that these method calls are in
another goroutine so that monitor does not get blocked as time goes on. If
there is a burst of messages, they will get run as workers free up.
The other interesting method here is getWorker(), which tries to pull
a worker off the channel if available. If nothing is there, this method blocks
until a worker is returned to the pool. If this doesn’t make sense to you,
check out how you can use channels for async communication across golang. The
one final note is that in the Process() method of the worker, it defers
a cleanup method which returns the given worker back to the global worker pool
once it has finished.
Our service has been running in production now for a few weeks, and we haven’t had any big issues so far. We make heavy use of statsd and grafana to help properly monitor errors and get a good bird’s eye view at any given moment. Between our aggressive error handling and the monitoring, this approach seems to be sustainable.
While not the most conventional way to handle recurring job processing for scikit-learn, it has worked quite well for our team.